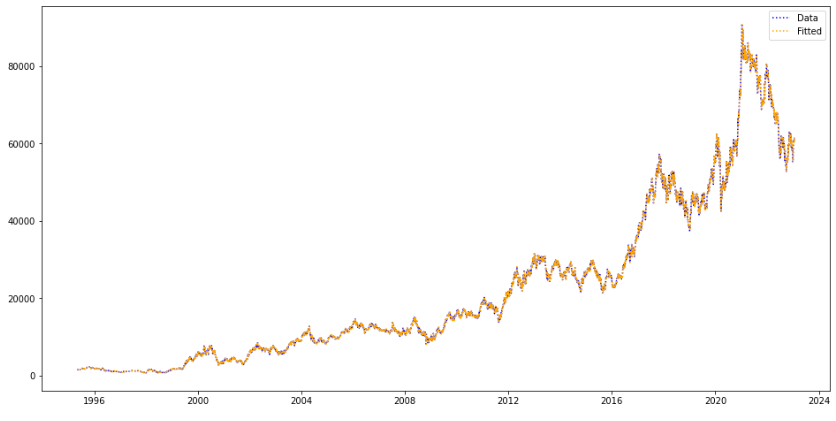
GitHub - SeungbeomDo/Time_Series_Analysis: Practical Codes for Time Series Modeling and Analysis Practical Codes for Time Series Modeling and Analysis - GitHub - SeungbeomDo/Time_Series_Analysis: Practical Codes for Time Series Modeling and Analysis github.com 1. 벡터 시계열 1.1. 벡터 시계열의 도입 이전 포스팅에서 다루었던 ARMA 모델 등은 단변량 시계열을 분석하는 모델이었다. 가령 주가 시계열 $\{X_{t}\}$은 주식의 가격이라는 하나의 대상을 시간에 걸쳐 관측한 값의 집합이다. $$\{..