저번 포스팅에서는 ARIMA 모델의 계수 p,d,q를 정할 때 ACF 및 PACF를 확인해서 정하는 방법을 소개했다. 그런데 이는 이론적인 것일 뿐 그렇게 만들어진 모델이 정말 좋은 성능을 내는 것은 아니다. 아마 가장 확실한 방법은 직접 여러 후보 파라미터셋들에 대하여 모델을 하나하나 만들어보고 비교하는 것이다. 이를 수행해주는 라이브러리를 소개한다.
ARIMA 모델로 적합할 시계열을 넣어주고, 후보 파라미터들을 지정해준다. 계절성 ARIMA인지 여부도 지정해줄 수 있다.
이전 포스팅에서 수익률 시계열이 정상 시계열인지 여부를 검정했으니 차분 계수는 0으로 한다. AIC를 기준으로 가장 좋은 모델 파라미터를 뽑으면 아래와 같다.
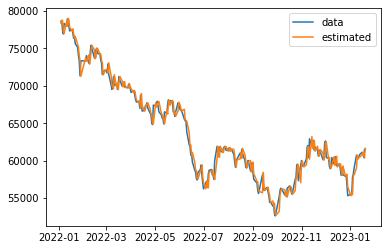
ACF와 PACF를 눈으로 확인하고 정한 파라미터는 (2,0,1)이었는데, AIC를 기준으로 제일 좋은 모델을 일일이 찾은 결과는 (1,0,2)가 나왔다. 수익률 시계열을 ARIMA(1,0,2)로 적합하고 2022년 이후에 대해서만 예측과 실제값을 아래와 같다.
예측오차 비율의 제곱합은 약 2.5% 정도가 나온다. 오늘 주가가 6만원이라면 대략 위아래로 1500원 정도의 오차가 있다는 이야기다.
그럼 여기서 잠깐, ARIMA 모델 파라미터를 AIC를 기준으로 결정한다고 했는데 AIC라는 게 뭔지 알아보자.
AIC(Akaike's Information Criterion)이란 ARIMA 모델의 성능을 지표하는 한 지표로서 아래와 같이 정의된다.
이때 L은 추정된 모델에서 주어진 시계열이 관측될 우도(Likelihood)이다. p와 q는 ARIMA의 파라미터이고, k는 절편이 포함된 여부를 나타내는 더미변수이다. 즉, AIC는 단지 로그우도가 큰 모델이 좋은 것이 아니라 너무 많은 독립변수를 사용하지 않는 것이 좋다는 것도 함께 반영하는 지표이다.
AIC는 낮을수록 좋다.
2. Backtesting
2.1. test set 분리
지금까지 진행한 내용을 완전히 믿으면 안 되는 게, train set과 test set을 분리하지 않고 그냥 주어진 샘플을 잘 적합하는 회귀계수를 찾았기 때문이다. 보다 완전한 검증을 위해서는 test set을 빼놓고 훈련시킨 모델을 사용해야 한다.
2022 이전의 데이터를 학습하여 2022년 이후의 주가를 맞추는 모델을 만들어보자.
학습데이터로부터 얻은 최적 파라미터는 (2,0,1)이고(AIC 기준), 학습데이터의 마지막날로부터 예측을 출발시킨다. 이때 예측을 이어나가는 방식을 설명하면 다음과 같다.
학습데이터의 마지막 수익률을 ARIMA 회귀식에 넣어 1일 후의 수익률을 예측한다.
1일 후 수익률의 예측값을 ARIMA 회귀식에 넣어 2일 후의 수익률을 예측한다.
...를 반복한다.
따라서 모형 자체의 오차뿐만 아니라 모형에 들어오는 독립변수의 오차까지 더해져서 모형의 오차는 점점 커진다. 아래는 그 결과이다.