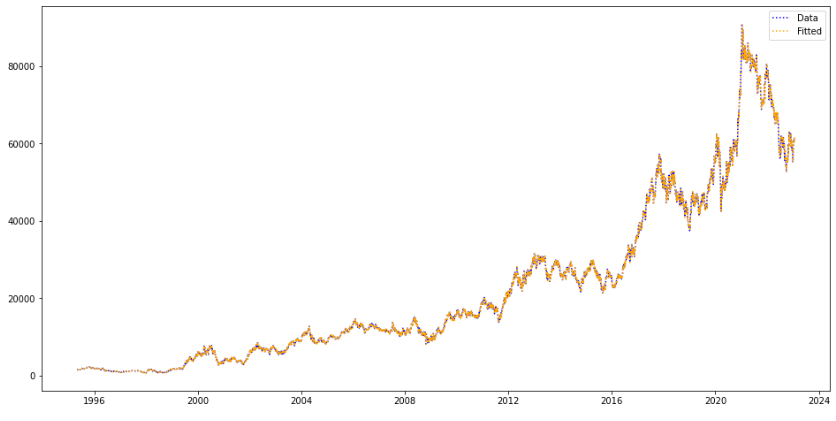
시계열 예측 모델링에 사용하는 Box-Jenkins-Method를 설명한다. 특별한 방법론이라기보다는, 전통적인 시계열 모델을 구현하는 데 있어서 사용하는 매뉴얼이라고 이해할 수 있다. 총 5가지 단계로 이루어지는데, 주어진 시계열의 정상성 여부를 테스트한다. 비정상 시계열일 경우 차분, 필터링 등 적당한 처리를 거쳐 정상화한다. ARMA 모델의 모수인 p와 q를 정한다. 모델의 계수들을 추정한다. 적합한 모델인지 알아보기 위해 계수 검정 및 잔차 검정을 실행한다. 최종 모델을 사용하여 예측한다. 이때 차분된 시계열을 역차분하여 원 시계열로 돌려준다. 그럼 한 단계씩 살펴보도록 하자. 1. 정상성 검정과 정상화 1.1. 정상성의 의의 첫 단계는 주어진 시계열의 정상성 여부를 파악하는 것이다. 간단한 방법..