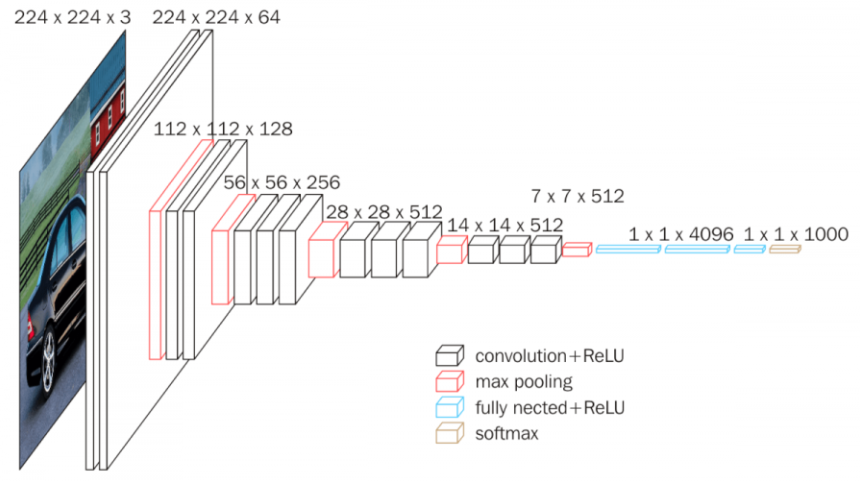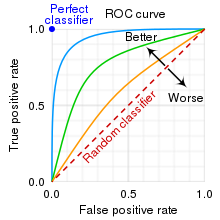
이전 글에서 지속 Confusion matrix란 (tistory.com) Confusion matrix란1. Confustion Matrix 이진 예측(분류 예측) 모델을 평가하는 대표적인 지표는 Confusion matrix이다. 주어진 데이터포인트를 양성(1) 또는 음성(0)으로 분류하는 문제에서, 데이터포인트의 실제 레이블과 seungbeomdo.tistory.com 4. F1-score: 최적의 양성 판단 비율을 찾기 레퍼런스에서는 F1-score라는 개념도 자주 나온다. F1-score는 정밀도와 재현율의 조화평균이다. F1=2×Prec×RecPrec+Rec
정밀도와 재현율 간에는 상충 관계가 존재한다. 그래서 F1-score를 사용해서 ..