1. 클러스터링의 개요
- 클러스터링(Clustering)이란 샘플 내의 대상들을 일정하게 분류하는 비지도학습 과제를 말한다. 가령 아래와 같은 2차원 변수 공간에 샘플들이 분포하고 있을 때, 샘플들을 각각의 집단으로 묶어내는 작업이다.

- 위 그림과 같은 상황에서, 직관적으로 세 개의 클러스터로 묶어내고 싶다는 생각이 들 것이다. 그러나 그런 기준들은 연구자의 직관에 의존하고 있어서 임의적이라는 한계를 갖는다. 클러스터링 기법들을 활용하면 임의성의 문제를 극복하고 샘플들을 일관적이고 합리적인 방식으로 묶어낼 수 있다.
- 나아가서 서로 특성이 다른 샘플들을 서로 다른 클러스터로 분류해 놓은 후에, 각 클러스터들이 어떤 특징을 갖는지 인사이트를 얻어낼 수 있다. 또는 원래 주어진 문제가 회귀 문제였다면, 샘플 전체에 대해서 회귀분석을 하는 것보다는 일정한 기준에 따라 동일한 특징을 공유하는 클러스터들을 만들고, 각 클러스터 내에서 회귀를 실시하면 보다 합리적인 결과를 얻을 수 있다.
- 대표적인 3가지의 클러스터링 기법을 공부해보도록 하자.
2. K-means Clustering
2.1. K-means 클러스터링의 알고리즘
- K-means Clustering이란, 샘플들로부터 k개의 중심점(centroid)을 찾고 각각을 중심점으로 하는 k개의 클러스터를 찾는 알고리즘이다. 가령 아래와 같은 샘플 분포에서 각각의 중심점을 찾고, 개별 샘플들은 자신과의 거리가 가장 가까운 중심점으로 모여 클러스터를 이루게 된다.
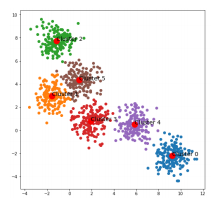
- K-means Clustering은 EM 알고리즘을 기반으로 한다. EM 알고리즘을 단계별로 설명하면 다음과 같다.
- 1. 변수공간에 임의의 k개의 중심점 좌표를 찍는다.
- 2. 각 샘플들은 k개의 중심점들 중 가장 가까운 중심점에 따라 클러스터를 할당받는다.
- 3. 각 클러스터의 중심점을 업데이트한다. 이때 클러스터의 중심점은, 그 클러스터에 속하는 샘플들과의 거리 제곱합이 최소화되도록 하는 점이다.
- 4. 업데이트된 중심점들에 대하여 다시 샘플들을 클러스터링한다.
- 2~4단계를 반복하면서, 더이상 중심점의 유의미한 업데이트가 일어나지 않을 때까지 지속한다.
- 이때 거리제곱합이 최소화되는 중심점을 찍는 단계를 E(Expection) 단계, 업데이트된 중심점 하에서 클러스터를 다시 모으는 단계를 M(Maximization) 단계라고 한다. 이 두 단계를 반복한다고 해서 EM 알고리즘이다.
2.2. K-means 알고리즘의 특징
- K-means 알고리즘은 초기에 주어진 중심점이 어디었는지에 따라 결과가 달라질 수 있는 문제가 있다. 따라서 임의성의 문제를 아예 배제하지 못한다.
- 또한 샘플 분포의 기하학적인 형태를 고려하지 못하고 단순히 유클리드 거리로만 클러스터링한다.
- 유클리드 거리를 가지고 클러스터링하기 때문에, 변수 공간의 차원이 증가할수록 계산 비용이 가파르게 증가하고 과대적합에 취약해진다.
- 아웃라이어의 존재에 민감하다. 아웃라이어와의 멀찍이 떨어진 거리가 중심점의 위치에 큰 영향을 주기 때문이다.
- 어쩌다보니 단점만 적었지만, K-means 알고리즘은 매우 직관적이고 단순하기 때문에 활용성은 굉장히 높다.
3. Hierarchical Clustering
3.1. 계층적 클러스터링의 알고리즘
- 계층적 클러스터링은 개별 샘플들을 여러 층의 클러스터링으로 묶는 방법이다. 가령 A,B,C,D,E,F,G,H 라는 샘플들이 있을 때, AB, CD, EF, GH를 각각 클러스터로 묶은 후 ABCD, EFGH를 그 상위 클러스터로 묶는 방법이다.
- 방금 설명한 방법은 Bottom-up Clustering이라고 하며 Agglomerative Clustering이라고도 부른다. 반대로 Top-down 방식의 클러스터링도 있는데, 여기서는 Agglomerative 방법만을 다룬다.
- Agglomerative 클러스터링의 알고리즘은 다음과 같다.
- 먼저 모든 샘플들의 거리에 대한 유사도 행렬을 구한다. 유사도 행렬이란, n*n 대칭행렬이며 (i,j) 원소는 i번째 행에 해당하는 샘플과 j번째 열에 해당하는 샘플 간의 거리로 주어진 행렬이다.
- 거리를 어떻게 측정할 것인가도 이슈가 된다. 단순히 유클리드 거리를 사용할 수도 있지만, 계층적 클러스터링에서 자주 사용하는 거리 척도는 Ward's Linkage라는 척도이다. 두 군집 A와 B가 합쳐졌을 때 오차제곱합이 증가하는 정도를 측정하는데, 정의식은 아래와 같다.
$$Ward = \Sigma_{X_{i} \in A \cup B} ||X_{i} - m_{A \cup B}||^{2} - [\Sigma_{X_{i} \in A} ||X_{i} - m_{A}||^{2} + \Sigma_{X_{i} \in B} ||X_{i} - m_{B}||^{2}]$$
- 여기서 $m_{K}$는 군집 $K$의 중심점을 말한다. 즉 두 군집이 합쳐진 후 군집의 편차제곱합과 합쳐지기 전 각 군집의 편차제곱합의 합을 말한다. 군집이 합쳐지고나면 각 샘플이 군집의 중심점과 거리가 더 멀어지기 때문에 와드 거리는 증가하게 되는데, 그 증가분이 가장 작도록 새로운 군집을 찾는 것이다.
- 와드 거리를 사용해 군집 간 유사도 행렬을 계산한 후에 와드 거리가 가장 작은 이들끼리 새로운 군집을 형성한다. 그 다음에 새로운 군집들 간 유사도 행렬을 다시 계산하고, ... , 반복해서 모든 샘플이 하나의 군집으로 나타날 때까지 지속한다. 초기에는 군집이 주어져있지 않으므로 각 샘플 자체를 하나의 군집으로 간주한다.
3.2. 덴드로그램(Dendrogram)
- 덴드로그램이란 계층적 클러스터링을 시각화하는 방법이다. 위에서 적은 계층적 클러스터링 알고리즘 예시를 보면서 덴드로그램이 어떻게 만들어지는지를 함께 이해해보자.
- 아래와 같이 초기에 A, B, C, D 샘플이 주어져있다고 하자. 1) 이들로부터 첫번째 유사도행렬을 와드거리를 가지고 계산한다. 2) 와드거리가 가장 작은 A와 D를 군집으로 묶는다. 3) 이제 AD, B, C의 3개의 군집으로 좁혀졌으므로 이들을 가지고 다시 와드거리를 계산한다. 그랬더니 AD와 C가 가장 가까운 것으로 나와서 ADC와 B라는 2개의 군집으로 좁혀졌다. 마지막으로 ADC와 B 간의 와드거리를 계산하고 최종적인 하나의 군집이 형성된다.

- 각 스텝에서 가장 가까운 군집들은 계층 트리에서 바로 옆에 위치하게 된다. 그리고 두 군집을 이어주는 가지의 길이는 유사도행렬에서 계산된 두 군집 간의 거리(여기서는 와드거리)를 뜻한다.
- 이처럼 어떤 군집들이 서로 가까운지, 그리고 서로 간의 거리는 얼마나 되는지를 나타내는 계층 트리가 완성되는데, 이 계층 트리를 덴드로그램이라고 한다.
- 덴드로그램이 만들어지고 나면 클러스터를 어떻게 정할지를 결정한다. 이는 원하는 클러스터의 수에 따라서 덴드로그램의 가지를 수평적으로 잘라냄으로써 얻어진다. 아래 그림 예시를 보면 된다.

3.3. Hierarchical Clustering의 특징
- 계층적 군집 방법의 특징은 '임의의 초기점' 개념이 없으므로 결과가 항상 동일하게 나온다는 것이다.
- 또한 군집을 몇개로 할지 미리 정하지 않고 나중에 가서 적당하게 군집 수를 정할 수 있다.
- 반면 계산 비용이 K-means 알고리즘보다 일반적으로 더 크다고 한다.
4. DB SCAN
4.1. DB Scan의 알고리즘
- 세번째 알고리즘은 DB SCAN(Density Based Spatial Clustering of Applications with Noise)이다. 이름에서 알 수 있듯이 밀도를 기반으로 클러스터링을 수행하며, 클러스터되지 못한 noise들도 그대로 남겨둘 수 있어서 이상치 탐지 모델로도 사용한다.
- DB Scan은 두 가지 하이퍼 파라미터를 가진다. 하나는 주어진 중심점으로부터의 거리 epsilon이고, 그 거리 내에 위치한 점들의 수 minPts이다. DB Scan은 epsilon 근방 내에 minPts개 이상의 점들이 존재하도록 하는 중심점들을 알고리즘이다. 아이디어 자체는 K-means 알고리즘이랑 비슷하기도 하고 별로 어렵지 않다.
- 그리고 두 중심점이 서로를 포함한다면 두 중심점은 하나의 군집으로 묶는 방식을 택한다.
- 중심점을 모두 찾은 후에 어떤 중심점과도 연결되지 못한 샘플은 noise 또는 아웃라이어로 남겨둔다는 강력한 장점이 있다.
4.2. DB scan의 특징
- DB scan의 특징은 군집의 수를 미리 정하지 않고 알아서 군집의 수를 알고리즘이 찾아준다는 것이다.
- 또한 기하학적인 특성을 보존하는 클러스터링이 가능하다.
- 아웃라이어에 강건하다는 것도 특징이다.
- 치명적인 단점은 밀도 기반의 군집화이기 때문에, 설정한 밀도보다 낮은 클러스터들은 클러스터로 묶어내지 못하고 그냥 다 노이즈로 처리해버린다는 것이다.
5. Clustering의 몇 가지 고려사항
- 클러스터링을 할 때 주요한 고려사항들이 있다. 첫째는 정규화가 필수적이라는 점이다. 대부분의 클러스터링 알고리즘은 변수 공간 상의 거리 계산을 사용하기 때문에 정규화를 반드시 해줘야 한다.
- 두번째는 클러스터의 수이다. 클러스터의 수가 얼마가 적당한지를 결정하는 것이 필요하다. 최적의 클러스터 수를 결정하기 위한 방법으로 대표적인 것은 Elbow method이다. 이는 클러스터의 수가 늘어남에 따라 모델의 성능이 변화하는 것을 나타내는 곡선이다. 예를 들어 모델 성능을 각 중심점과의 오차제곱합 $\e$라고 한다면

- 이때 Elbow point를 찾는 것이 핵심이다. Elbow point란, 클러스터 수의 증가에 따른 오차의 감소 속도가 유의하게 느려지게 되는 포인트를 말한다. 팔꿈치랑 비슷하게 생겼다고 해서 이렇게 부르나보다. 이 Elbow point가 최적의 클러스터 개수가 된다.
- 세번째는 클러스터링 결과의 성능 평가이다. 일반적으로 각 클러스터의 중심점으로부터의 편차제곱합을 성능치로 사용한다. 하지만 클러스터의 쌍대 목표는 군집 내 분산을 최소화하면서 군집 간 분산을 최대화하는 것이다. 편차제곱합은 군집 내 분산만을 측정하는 지표이므로, 아쉬움이 있다.
- 대안으로 제시하는 것이 실루엣 계수(Silhouette Coefficient)이다. i번째 샘플의 실루엣 계수는 다음과 같이 계산한다.
$$S(i) = \frac{b(i) - a(i)}{max\{a(i), b(i)\}}$$
- 여기서 a(i)는 i번째 샘플과 동일 클러스터에 속한 다른 샘플들과의 평균 거리이다. b(i)는 i번째 샘플과, 그와 다른 각각의 클러스터에 속한 샘플들과의 평균거리들의 최소값이다. a(i)는 동일 군집 내 분산도를 측정하므로 작을수록 좋고, b(i)는 다른 군집과의 거리를 측정하므로 클수록 좋다. 분모는 그냥 정규화(-1과 1 사이)를 위한 것이다.
- 개별 샘플의 실루엣 계수를 계산한 후 각 클러스터에 속한 샘플들의 실루엣 계수의 평균들을 계산한다. 그리고 각 클러스터의 실루엣 계수 평균 중 최댓값이 클러스터링 결과를 평가하는 전체 실루엣 계수가 된다. 실루엣 계수가 1에 가까울수록 클러스터링이 잘 되었다고 해석한다.
6. 실습
- 학력이나 기업규모 등의 변수가 근로자의 임금에 미치는 영향을 알아보고 싶다고 하자. 이때 고려할 사항은 모든 근로자집단이 동질적이지 않다는 것이다. 예컨대 학력이 임금에 미치는 영향은 플러스일 것으로 생각되지만, 근로자가 속한 산업의 특성에 따라 차이가 있을 수 있다.
- 이런 문제를 다루기 위해서, 근로자들을 클러스터링한 후 각각의 근로자 클러스터 내에서 회귀분석을 하는 것을 생각해보자. 클러스터된 근로자들은 모르긴 몰라도 동일한 특징을 공유하는 근로자들끼리 모였을 것이므로 언급한 문제가 완화되리라 기대할 수 있다.
- 클러스터링 효과가 극대화되기 위해서는 클러스터링이 이루어지는 변수 공간의 축들이 효율적으로 재생성될 필요가 있다. LDA 방법을 통해서 임금을 잘 설명하는 주성분을 생성해보자. 당연히 정규화를 실시한 후 해야 한다. Standard Scaling을 거친 임금을 3개 구간으로 균등분할해 임금 레이블을 만든 후 LDA로 차원축소하여 2개의 주성분을 사용했다.
y_label = np.digitize(y, bins = [0.33, 0.66])
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components = 2)
X_lda = lda.fit_transform(X, y_label)
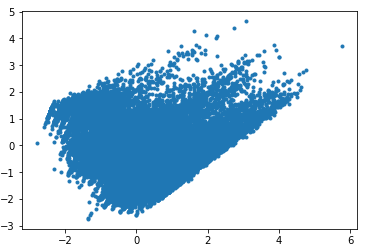
X_lda = pd.DataFrame({'lda_1':X_lda[:, 0], 'lda_2':X_lda[:, 1]})- LDA를 거친 후 주성분 공간에 근로자들을 나타내면 아래와 같다. 각각의 점들은 근로자를 나타낸다.
- Kmeans 방법으로 근로자들을 클러스터링한 결과는 아래와 같다.
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3)
X_km = km.fit_predict(X_lda)
X_lda['K_means'] = X_km
plt.plot(X_lda[X_lda['K_means'] == 2]['lda_1'], X_lda[X_lda['K_means'] == 2]['lda_2'], '.', color = 'blue', alpha = 0.5)
plt.plot(X_lda[X_lda['K_means'] == 1]['lda_1'], X_lda[X_lda['K_means'] == 1]['lda_2'], '.', color = 'red', alpha = 0.5)
plt.plot(X_lda[X_lda['K_means'] == 0]['lda_1'], X_lda[X_lda['K_means'] == 0]['lda_2'], '.', color = 'green', alpha = 0.5)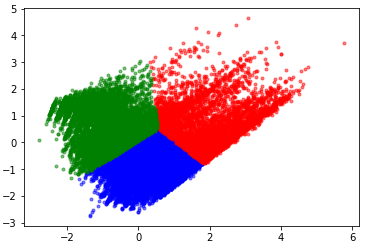
- 클러스터링의 유효성을 실루엣 계수로 평가한 결과 0.4 정도가 나왔다. 썩 나쁘지는 않은 수치이다.
import sklearn.metrics as metrics
from sklearn.metrics.cluster import silhouette_score
coef_km = metrics.silhouette_score(X_lda.iloc[:, :2], X_km)
print('Silhouette score is {}.'.format(coef_km))- 클러스터 내에서 임금의 평균을 구해보았다. 임금수준이 상, 중, 하인 세 개의 클러스터로 분할되었다는 것을 알 수 있다. LDA 방법으로 임금에 대해 차원 축소를 했기 때문에 임금 수준이 클러스터링되는 데 중요한 기준으로 자연스럽게 반영된 것이다.
X['K_means'] = X_km
X_lda_df = X.copy()
X_lda_df['income'] = y
X_lda_df.groupby('K_means')['income'].mean()
plt.hist(X_lda_df[X_lda_df['K_means']==0]['income'], bins = 100, color = 'blue')
plt.hist(X_lda_df[X_lda_df['K_means']==1]['income'], bins = 100, color = 'red')
plt.hist(X_lda_df[X_lda_df['K_means']==2]['income'], bins = 100, color = 'green')
plt.show()

- 각각의 클러스터 내에서 임금을 설명하는 다중회귀분석을 실시했다. 클러스터별로 독립변수의 회귀계수가 모두 다르게 나타났다.
X_0 = X_lda_df[X_lda_df['K_means']==0].drop(columns = ['income', 'K_means'])
y_0 = X_lda_df[X_lda_df['K_means']==0]['income']
X_1 = X_lda_df[X_lda_df['K_means']==1].drop(columns = ['income', 'K_means'])
y_1 = X_lda_df[X_lda_df['K_means']==1]['income']
X_2 = X_lda_df[X_lda_df['K_means']==2].drop(columns = ['income', 'K_means'])
y_2 = X_lda_df[X_lda_df['K_means']==2]['income']
for i, X, y in zip([0,1,2], [X_0, X_1, X_2], [y_0, y_1, y_2]):
lr_model = LinearRegression()
lr_model.fit(X, y)
print('===========================================')
print('OLS coefficients for {}th cluster'.format(i))
print(pd.DataFrame({'variables' : X.columns, 'coefficients':lr_model.coef_}))
- 가령 임금수준이 가장 높은 0번째 클러스터에서는 학력, 경력, 성별, 정규직 여부의 중요도가 높았고 임금이 가장 낮은 1번째 클러스터에서는 학력과 경력의 중요성이 상당히 제거되었다. 중간수준인 2번째 클러스터에서는 학력과 경력의 중요성이 두 클러스터의 중간 정도로 나타났다. 클러스터마다 이런 큰 차이가 있음에도 불구하고 하나의 클러스터로 뭉뚱그리면 그만큼 변수 중요도의 해석도 뭉뚱그려질 수 있다.
- 이는 고임금 근로자 집단일수록 학력과 경력 등의 합리적 요인이 큰 영향을 갖는다는 것을 보여준다. 그와 동시에 고임금 근로자 집단에서 성별과 정규직 여부에 따른 임금 격차도 가장 크게 나타났다. 물론 엄밀한 학술적 분석을 한 것이 아니고 클러스터링을 데이터분석에서 어떻게 활용할 수 있는가를 시험하기 위해 나이브하게 분석한 결과이다.
'머신러닝&딥러닝' 카테고리의 다른 글
| Deep Learning #2 CNN(합성곱 신경망) (0) | 2023.02.17 |
|---|---|
| Deep Learning #1 딥러닝 기초: 심층신경망의 구조와 간단 코드 실습 (1) | 2023.02.15 |
| Machine Learning #4 차원 축소 : 신용카드 연체 여부 예측 (0) | 2023.02.09 |
| Machine Learning #3 Decision Tree & Ensemble : 신용카드 연체 예측 (0) | 2023.02.08 |
| Machine Learning #2 Logistic Regression & SVM : 정규직 여부 분류 모델 (0) | 2023.02.07 |