- 이전 포스팅에서는 CNN의 기본적인 골격을 살펴보았다. 여기서는 CNN의 발전 과정에서 많은 기여를 한 3가지의 대표적인 CNN 모델을 소개한다.
[DL] CNN의 개요
1. Computer Vision Computer Vision(CV) 문제는 컴퓨터가 이미지를 잘 이해할 수 있도록 하는 과제를 말한다. 가령 자율주행 자동차가 지금 앞에 있는 것이 사람인지 텅 빈 도로인지를 잘 파악할 수 있도록
seungbeomdo.tistory.com
1. VGG Net
1.1. VGG Net의 개요
- VGG Net은 2014년 이미지넷 인식 대회에서 준우승을 한 모델이다. 이전의 뉴럴넷 모델들에 비해 압도적으로 많은 레이어들을 사용해서 Deeper CNN 모델의 시초가 되었다.
- VGG Net은 레이어의 개수에 따라 VGG-13, VGG-16, VGG-19 등으로 구분된다.
1.2. VGG Net의 구조
- VGG-16을 예시로 하여 VGG Net의 구조를 살펴보자. 아래의 그림을 보면 풀링 레이어와 활성화함수를 제외하고 13개의 컨볼루션 레이어와 FC 레이어로 이루어져있다.
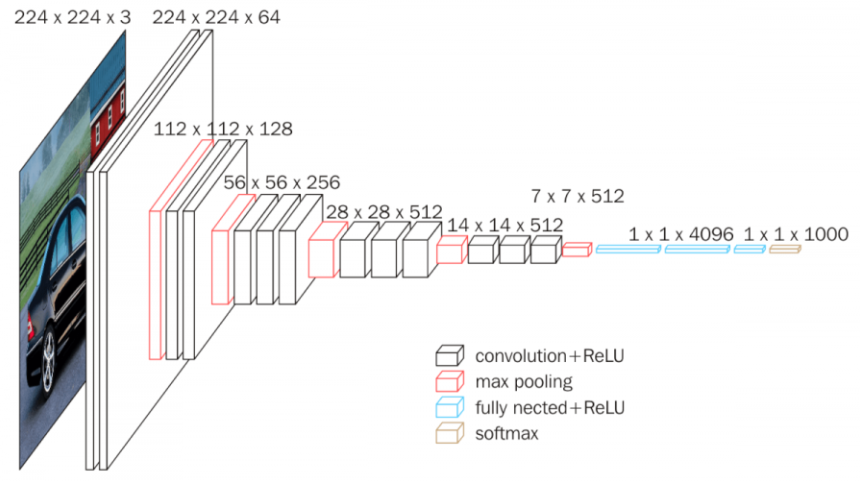
- 한 눈에 보기에도 매우 긴 뉴럴넷인데, 이렇게 깊은 레이어들을 구현하기 위해서 VGG Net은 3*3 커널만을 사용한다. 이전 포스팅에서도 살펴보았듯이 커널의 사이즈가 작을수록 차원이 천천히 줄어들어서 더 깊은 네트워크를 구현할 수 있게 된다.
- 그림을 보면 빨간색 맥스풀링이 있기 전까지는 특성맵의 사이즈가 줄어들지 않는 것을 확인할 수 있다. 작은 커널 사이즈를 사용하면서 동시에 제로 패딩을 통해 특성맵의 사이즈가 줄어들지 않도록 만든 것이다.
2. Google Net
2.1. Google Net의 개요
- Google net은 VGG Net이 준우승을 한 2014년 대회에서 우승을 한 모델이다. VGG Net보다 훨씬 특이한 모델 구조를 가지고 있다.

- Google Net은 크게 4가지의 레이어 그룹으로 구분된다. Stem Network, Inception Modules, Auxiliary Classifier, 그리고 Global Average Pooling이다. 이름이 제각기 무시무시하지만 하나씩 뜯어보면 이해하기에 그렇게 어려울 것은 없다.
2.2. Google Net의 구조
2.2.1. Stem Network
- 1번째 단계인 Stem Network는 뉴럴넷의 초반부에 큰 사이즈의 커널을 통과시켜 특성맵의 차원을 빠르게 줄이는 역할을 한다. 이 부분에서는 7*7 사이즈 커널을 사용하고 있다.
2.2.2. Inception Network
- 2번째 단계인 Inception Network는 마치 영화 인셉션에서 꿈 속에 개입하는 것과 유사한 역할을 한다. 바로 뉴럴넷의 중간에 인셉션하여 작은 뉴럴넷을 새로 만드는 것이다. 인셉션넷의 구조는 아래와 같다.

- 주어진 입력으로부터 위와 같이 여러 갈래로 컨볼루션을 뽑아내고, 인셉션을 마치면서 컨볼루션된 특성맵들을 이어붙인다(concatenate). 초반에 Stem Net으로 인해 차원 수가 확 줄어들었음에도 인셉션넷을 통해 충분한 특성들을 뽑아낼 수 있는 것이다.
2.2.3. Auxiliary Classifier
- 3번째 단계인 Auxiliary Classifier는 중간 단계에서 예측 오차를 계산해주는 파트이다. Google Net은 모델의 깊이도 깊고, 인셉션넷의 존재로 인해 그래디언트 소실 문제에 취약할 수 있다. 따라서 뉴럴넷을 모두 마친 후에 예측 오차를 계산하는 것이 아니고 중간 중간에 예측 오차를 계산함으로써 그래디언트 소실 문제에 대응한다.
- 단, Auxiliary Classifier는 train 중에만 사용하고 실제 모델로 작업을 할 때는 제거한다.
2.2.4. Global Average Pooling
- GAP는 이전 포스팅에서도 다루었던 내용으로, FC 레이어로 들어가기 이전에 컨볼루션된 특성맵을 채널마다 평균내는 방식으로 flatten 해주는 스킬이다.
- 이전까지는 컨볼루션된 특성맵을 단순히 flatten해주는 방법을 썼다고 한다. 이렇게 되면 주어진 특성맵의 가로*세로*채널이 FC 레이어의 인풋벡터의 길이가 되므로 연산량도 매우 크고 파라미터가 너무 많아진다는 문제가 있었다.
3. ResNet
3.1. ResNet의 개요
- ResNet은 2015년에 우승을 한 모델이다. VGG Net이나 Google Net에 비해서도 압도적으로 많은 레이어 수를 사용했으며 잔차를 학습한다는 획기적인 아이디어를 담았다.
- 이후에도 ResNet의 아이디어를 차용한 모델들이 한동안 주류였다고 한다.
3.2. ResNet의 구조
- ResNet은 Google Net과 동일하게 초반에 7*7 사이즈의 큰 커널을 사용해서 특성맵의 차원을 빠르게 줄인다. 또한 FC 레이어로 들어가기 이전에 GAP를 사용한다. 동시에 VGG Net과 유사하게 3*3 커널들을 사용해서 뉴럴넷의 깊이를 늘린다.
- ResNet의 가장 큰 특징은 주어진 특성맵으로부터 주어진 정보는 보존하면서 추가적인 학습을 진행한다는 점이다. 이런 아이디어를 구현하기 위해 아래 그림과 같은 구조로 컨볼루션을 진행한다. 눈여겨봐야할 것은 identity mapping이다.

- 주어진 특성맵은 컨볼루션을 거치는 것과 동시에 바로 몇 단계의 레이어(Residual Block)를 건너뛰어 concatenate된다.... 사실 이 구조가 어떤 원리로 잔차를 학습한다는 것인지 직관적으로 느끼기는 쉽지 않다. 부족한 이해로나마 설명해보면:
- 언급한 구조 하에서 훈련이 어떻게 이루어질지 상상해보자. 뉴럴넷의 훈련은 그래디언트 방향으로 파라미터를 조정하면서 오차를 줄여나가는 것이다.
- 그런데 Identity mapping으로 인해 몇 단계 뒤에 자기 자신과 동일한 값이 있다고하자. 그러면 여기서부터 전파되어 온 (Global)그래디언트에는 이미 자기 자신의 정보가 반영되어 있다. 따라서 자기 자신을 제외한 부분만 훈련 대상으로 남게 된다.
'머신러닝&딥러닝' 카테고리의 다른 글
| Deep Learning #5 NLP의 개요 (0) | 2023.02.28 |
|---|---|
| Deep Learning #4 RNN(순환신경망) (0) | 2023.02.23 |
| Deep Learning #2 CNN(합성곱 신경망) (0) | 2023.02.17 |
| Deep Learning #1 딥러닝 기초: 심층신경망의 구조와 간단 코드 실습 (0) | 2023.02.15 |
| Machine Learning #5 클러스터링 : 근로자 임금 분포 클러스터링 (0) | 2023.02.12 |