DeepAR: Probabilistic Forecasting with Autoregressive Recurrent Networks
Probabilistic forecasting, i.e. estimating the probability distribution of a time series' future given its past, is a key enabler for optimizing business processes. In retail businesses, for example, forecasting demand is crucial for having the right inven
arxiv.org
시계열 예측에 사용되는 RNN의 한 응용인 DeepAR 모형을 공부해보자.
GitHub - SeungbeomDo/Time_Series_Analysis: Practical Codes for Time Series Modeling and Analysis
Practical Codes for Time Series Modeling and Analysis - GitHub - SeungbeomDo/Time_Series_Analysis: Practical Codes for Time Series Modeling and Analysis
github.com
1. DeepAR
1.1. DeepAR의 특징
- DeepAR은 주어진 시계열을 예측하는 자기회귀 구조를 가지고 있다. 동시에 복수의 시계열들을 한 번에 예측하는 것(VAR과 유사)이 가능하다.
- 가장 두드러지는 특징은 예측값을 스칼라나 벡터(deterministic value)가 아닌 확률분포로 제시해준다는 것이다.

1.2. DeepAR의 구조
1.2.1. 기본 구조
- DeepAR의 인풋은 벡터 $\vec{Z_{t}}$의 시퀀스이며, 아웃풋은 예측 시계열 $\vec{Z_{t+i}} \; (i>0)$에 대하여 가정된 확률분포 하에서의 모수 벡터 $\vec{\theta_{t}}$이다.
- DeepAR의 인풋 시퀀스는 conditioning range, 아웃풋 시퀀스는 prediction range라고 부른다.
- DeepAR은 Encoder-Decoder의 구조를 가진다. Encoder 부분은 시계열의 시퀀스를 받아 hidden state를 발생시키며, Decoder 부분은 hidden state로부터 가정된 확률분포의 모수를 발생시킨다.
- 아래 그림은 시계열을 벡터로 표시하지 않고, 벡터 시계열의 각 원소 시계열에 대하여 DeepAR의 구조를 도식화한 것이다.

- Encoder 파트는 일반적인 RNN과 동일하다. Encoder 파트에서 발생하는 hidden state는 이전 time step에서 주어진 hidden state와 현재의 인풋, 그리고 LSTM cell의 파라미터 집합 $\Theta$의 함수이다. g는 히든 레이어들을 거친 결과를 뜻하는 함수이다.
$$\vec{h_{t}} = g(\vec{h_{t-1}}, \vec{z_{t-1}}, \Theta)$$
- Decoder 파트에서 확률분포의 모수 벡터 $\vec{\theta_{t}}$는 hidden state의 함수이다. 여기서도 함수 f는 Encoder 파트의 히든 레이어들을 의미한다.
$$\vec{\theta_{t}} = f(\vec{h_{t}})$$
1.2.2. 훈련 방법
- RNN이므로 BPTT 방법으로 모델 파라미터들을 훈련한다. 이때 손실함수는 negative Log-likelihood이다. 로그우도함수는 예측된 벡터 시계열 시퀀스(즉 prediction range)에 대하여 계산된 값이다.
$$\mathcal{L} = \Sigma_{i=1}^{N}\Sigma_{t=1}^{T}\, ln\, P(Z_{i,t}|\theta(\vec{h_{i,t}}))$$
- i는 벡터 시계열의 원소를, t는 prediction range의 t번째 값을 나타낸다.
1.2.3. 검증 방법 관련
- 훈련 과정에서는 conditioning range의 label이 모두 주어지지만, 검증 과정에서는 첫번째 conditioning range의 마지막 벡터까지만 주어져있다. 따라서 두번째 conditioning range의 벡터들은 이전 단계에서 모형이 예측한 벡터(논문에는 안 나와있는데 아마 예측된 확률분포의 median)를 사용한다.
- 따라서 forecast sight가 길어질수록 모형 오차에 인풋 벡터 오차까지 포함되어 예측 오차는 점점 커진다는 단점이 있다.

2. DeepAR 코드 실습: 주가수익률 시계열 벡터의 확률분포 예측
2.1. 데이터 및 라이브러리 임포트
- DeepAR을 지원하는 GluonTS 라이브러리를 사용한다.
!pip install "gluonts[torch,pro]"
!pip install "gluonts[mxnet,pro]"
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from gluonts.dataset.pandas import PandasDataset
from gluonts.dataset.split import split
from gluonts.mx import DeepAREstimator, Trainer
from gluonts.dataset.common import ListDataset
from gluonts.evaluation.backtest import make_evaluation_predictions
from gluonts.mx.trainer.learning_rate_scheduler import LearningRateReduction
from gluonts.mx.trainer.model_averaging import ModelAveraging, SelectNBestSoftmax, SelectNBestMean
from gluonts.mx.distribution import StudentTOutput, GaussianOutput, LaplaceOutput, GenParetoOutput- 코스피200 지수의 일별 수익률(로그수익률)을 사용한다. 2022년 6월 ~ 10월 중 101거래일 동안의 데이터를 사용했다.

2.2. Window Rolling
- 훈련 및 테스트에 window rolling 방법을 사용할 것이다. 왜냐하면 위에 언급했듯이 test 과정에서 첫번째 conditioning range 이후의 라벨은 주어져있지 않으므로 예측오차가 증폭되는 문제가 있기 때문이다.
- 이를 해결하기 위해서 사용하는 window rolling이란 다음과 같은 과정이다. conditioning range가 C, prediction range가 P일 때,
- 1일~C일의 데이터를 사용해서 C+1일~C+P일의 수익률을 예측하는 훈련을 한다. 그 결과를 model 1이라고 한다.
- 2일~C+1일의 데이터를 사용해서 C+2일~C+P+1일의 수익률을 예측하는 훈련을 한다. 그 결과를 model 2라고 한다.
- ... N일~C+N-1일의 데이터를 사용해서 C+N일~C+P+N-1일의 수익률을 예측하는 훈련을 한다. 그 결과를 model N이라고 한다. 이제 훈련 과정은 종료된다.
- model 1을 사용해서 2일~C+1일을 conditioning range로 하여 C+2일~C+P+1일의 수익률을 예측한다.
- model 2를 사용해서 3일~C+2일을 conditioning range로 하여 C+3일~C+P+2일의 수익률을 예측한다.
- ... model N을 사용해서 N+1일~C+N일을 conditioning range로 하여 C+N+1일~C+P+N일의 수익률을 예측한다.
- 이 방법을 사용하면 test set을 오염시키지 않으면서도 test 과정에서 발생하는 conditioning range 문제를 해결할 수 있다. 또한 이는 금융시계열 분석에서 자주 사용되는 방법이기도 하다. 왜냐하면 금융시계열은 자기회귀적 패턴이 변화하는 경향이 있어서 지속적으로 최신 데이터로 재훈련을 해주어야 하기 때문이다.
- conditioning range는 10, prediction range는 1로 하자. 즉 10일 간의 수익률 시계열을 가지고 이후 1일의 수익률을 예측한다.
- window size는 conditioning range + prediction range로 구한다. 물론 더 길게 해도 되는데 최소한 이것보다는 길거나 같아야 한다. 왜냐하면 한 training window 내에서 conditioning range로 prediction range를 예측하는 훈련을 하기 때문이다. 아무튼 window size는 11이 된다.
- step size는 window를 몇 칸씩 밀 것인가를 의미하는데, 통상 1로 하면 무리가 없을 것이다.
- 훈련 및 검증에 사용되는 데이터가 101 거래일의 데이터이므로 window의 총 개수는 101 - 11 + 1 = 91개이다.
2.3. 모델 구현
- DeepAREstimator 함수로 쉽게 DeepAR 모델을 구현할 수 있다. 파라미터들은 굳이 설명하지 않아도 대충 느낌이 올 것이다.
callbacks = [
ModelAveraging(avg_strategy=SelectNBestMean(num_models=10))
]
estimator = DeepAREstimator(
freq="1D", #
prediction_length=1,
context_length=10,
num_cells=20,
num_layers=1,
dropout_rate=0.1,
distr_output=GaussianOutput(),
trainer=Trainer(epochs=10,
callbacks=callbacks)
)
2.4. 모델 훈련
- 한 번의 윈도우마다 하나의 모델을 훈련하여 저장한다.
models = []
for i in range(0, int((len(df_pr) - window_size)/step_size + 1), step_size):
print(f"train window {i+1} of total {int((len(df_pr) - window_size)/step_size + 1)} windows")
window_df_train = df_pr.iloc[i:i+window_size]
window_data_train = create_dataset(window_df_train)
print(window_data_train)
model = estimator.train(window_data_train)
models.append(model)
2.5. 예측값 생성
- DeepAR 모델은 예측값을 확률분포로 알려주는데, 정확히는 확률분포 시뮬레이션을 통해서 예측값의 샘플을 생성해준다. 일단 여기서는 1번 예측할 때마다 100개의 샘플을 생성했다.
- 각각의 모델마다 각각의 test window를 적용해서 예측값을 만들어준다. 즉 모델 1은 2일 ~ 11일 수익률을 사용해서 12일의 수익률을 예측한다. 모델 2는 3일 ~ 12일 수익률을 사용해서 13일의 수익률을 예측한다.
num_samples = 100
forecasts = []
for i, model in enumerate(models):
print(f"test window {i+1} of total {(len(df_pr) - window_size)/step_size + 1} windows")
window_df_test = df_pr.iloc[i+1:i+window_size+1]
window_data_test = create_dataset(window_df_test)
forecast_it, ts_it = make_evaluation_predictions(
dataset=window_data_test, predictor=model, num_samples=num_samples
)
forecasts.append(list(forecast_it)[0])- 아래는 예측일마다 해당하는 예측값 샘플들을 저장하는 과정이다.
pred_length = forecasts[0].samples.shape[1]
preds = np.zeros((len(forecasts), num_samples)) #91 거래일동안 1일씩 예측하면서 100개의 샘플들 생성
for i, f in enumerate(forecasts):
preds[i, :] = f.samples.squeeze()- mean estimator를 예측값으로 하고 99% 신뢰구간을 구한다. 이 둘은 모두 예측 샘플로부터 계산되는 값이다.
mean = np.mean(preds, axis=1)
p05 = np.percentile(preds, 0.5, axis=1)
p995 = np.percentile(preds, 99.5, axis=1)
plt.plot(df_pr.index[-len(mean):], df_pr['Return'].iloc[-len(mean):])
plt.plot(df_pr.index[-len(mean):], mean)
plt.fill_between(df_pr.index[-len(mean):], p05, p995, alpha=0.2)
plt.xlabel("Date")
plt.ylabel("Stock Return")
plt.xticks(rotation = '90')
plt.legend(["Actual", "Predicted", "99% Confidence Interval"])
plt.show()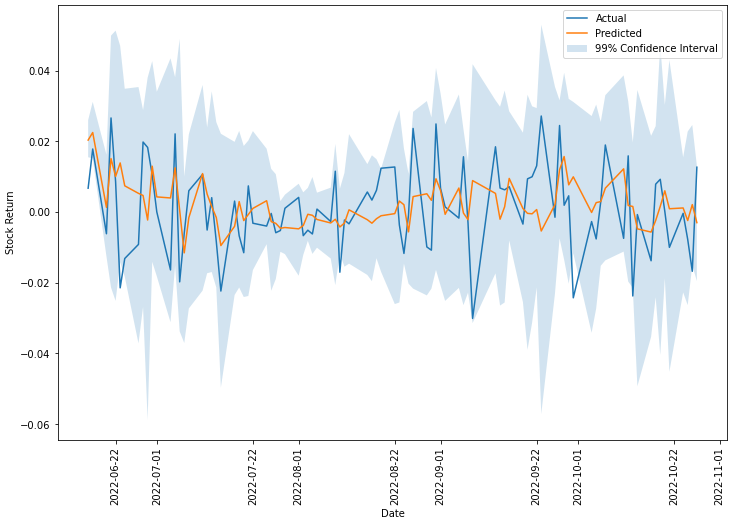
'시계열&계량경제학' 카테고리의 다른 글
| 계량경제학 #2 비정규 가정 하에서 OLS 추정량의 성질 (0) | 2023.05.14 |
|---|---|
| 계량경제학 #1 고전적 선형회귀 모형 (0) | 2023.05.11 |
| 시계열 분석 #11: VAR 모형의 이슈들 (0) | 2023.02.15 |
| 시계열 분석 #10 벡터자기회귀(VAR) (0) | 2023.02.14 |
| 시계열 분석 #9 ARCH & GARCH (0) | 2023.02.11 |